Numerical Methods in Accelerator Physics
Lecture Series by Dr. Adrian Oeftiger
Guest Lecture by Dr. Andrea Santamaria Garcia and Chenran Xu

Lecture 11
Run this notebook online!
Interact and run this jupyter notebook online:
Also find this lecture rendered as HTML slides on github $\nearrow$ along with the source repository $\nearrow$.
Run this first!
Imports and modules:
from config import *
%matplotlib inline
Refresher!
- closed orbit distortion due to dipole field errors
- periodic and non-periodic (propagated) solutions, $x_\mathrm{COD}(s)$ and $x_\mathrm{prop}(s)$
- local orbit correction: 3-corrector bump
- orbit response matrix $\Omega_{ij} = d x_i / d\Theta_j$
- global orbit correction: singular value decomposition (SVD) algorithm
Today!
- Bayesian Optimization Theory
- Implementation of Algorithm with Gaussian Processes
- Application to Beam Positioning and Focusing in a Linac
Abbreviations used in this notebook
- BO: Bayesian Optimization
- GP: Gaussian Process
Jargon
These terms are used interchangeably:
- Objective, metric, target function: $f(x)$ an unknown (black-box) function, for which the value is to be optimized (here: maximization)
- Observation, function evaluation, function query, data point: $y=f(x)$, the value of function $f$ at a particular value of $x$
- Feature, tuning parameter, "knob", dimension, actuator: $x_i = x_0, x_1, ...$, dimensions of your problem, correlated parameters the algorithm will vary
- Search space, bounds, optimization range: a (continuous) parameter space where the input parameters are allowed to be varied in the optimization
Part I: Bayesian Optimization Theory
Bayes' Theorem
Bayes' theorem is used for statistical inference, i.e. the process of using data analysis to infer properties of an underlying distribution of probability, or in other words, the process of drawing conclusions from data subject to random variations. The Bayes' theorem reads:
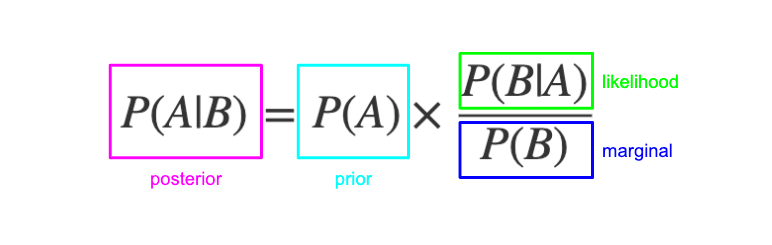
image from Bayes' Rule – Explained For Beginners
- $A, B$ are events, where $A$ can be interpreted as our hypothesis and $B$ as getting evidence
- $P(A|B)$ is the posterior probability of event $A$ happening given that event $B$ is observed, or the probability that the hypothesis is true given the evidence.
- $P(B|A)$ is the likelihood probability the conditional probablity of observing $B$ given $A$, or the probability of seeing the evidence if the hypothesis is true.
- $P(A), P(B)$ are the independent probabilities of observing $A$ and $B$, where:
- $P(A)$ is know as the prior probability, or probability that a hypothesis is true before any evidence (observation) is present
- $P(B)$ as the marginal probability, or probability of observing the evidence
Bayes' Theorem
Usually when we apply Bayesian optimization to a problem of our choice we make sure that when we query $f(x)$ we always get an observation $y$ back, so the probability of getting new samples is always 100%, i.e., $P(B) = 1$
Thus the Bayes' theorem reads $$P(A|B) \propto P(B|A) P(A),$$
i.e. the posterior probability is proportional to the prior times the likelihood probabilities.
Why use it?
Bayesian inference links the degree of belief in a hypothesis before and after accounting for evidence (observations), so it's ideal for building a probabilistic model and updating it sequentially as new data is gathered:

image from Bayes’ theorem
Bayesian Optimization
Bayesian optimization (BO) is a sequential algorithm to globally optimize an unknown function $f(x)$. In other words, it solves problems of the form
$$\text{max}_{x \in N} f(x),$$where $N$ is a set of observations.
The steps taken by a BO algorithm are the following:
- Bayesian optimization treats $f(x)$ as a random function and places a prior over it. The prior might contain previous observations (informed prior) or no information at all. These probability distributions are drawn from a probabilistic model like Gaussian Processes (more information here).
- We gather new observations (getting the value of $f(x)$ at particular $x$ points).
- The posterior distribution is obtained by applying Bayes' theorem.
- The posterior distribution is used to build an acquisition function that determines the next query point (more information here).
Acquisition function
The acquisition function $\alpha$ is:
- Built on the GP posterior,
- Controls the behavior of optimization by balancing exploration and exploitation to minimize the number of function queries (observations).
- For the standard version of BO, the next sample point is chosen at $\mathrm{argmax}(\alpha)$.
- In this tutorial we will introduce two widely used acquisition functions: the expected improvement (EI) and the upper confidence bound (UCB).
Gaussian Process (GP)
Introduction
A Gaussian Process (GP):
- is a way to construct your prior and posterior distributions.
- is a collection of random variables, where every linear combination of them is normally distributed.
- can be used as a probabilistic model (surrogate model) of the objective function $f(x)$.
- one can consider it like a function generator, where all the functions drawn from the model will follow specific statistical properties.
A GP can be fully described by it's mean $\mu$ and covariance function $k(\cdot,\cdot)$ $$f(x) \sim \mathcal{GP}(\mu(x), k(x,x'))$$
where $x$ and $x'$ are points in the input space.
Note: in GP regression, one usually denotes $x'$ as the observed points, and $x$ as the continuous variable.
Gaussian Process (GP)
Definitions
Kernel or covariance function $k(\cdot,\cdot)$, is just a general name for a function $k$ of two arguments mapping a pair of inputs $x \in \mathcal{X}, x' \in \mathcal{X}$ into $\mathbb{R}$
- is the basic building block of GPs
- encodes the assumptions about the function we wish to learn
- is a measure of how much two random variables (features) vary together (a measure of similarity)
Covariance matrix : given a set of points $\{x_i\}$ we can compute the covariance matrix $K$ whose entries are $K_{ij}=k(x_i, x_j)$, where $k$ is the covariance function.
Prior mean $\mu(x)$: prior belief on the averaged objective function values, usually set to a constant if the function behavior is unknown.
Gaussian process regression (GPR), also formerly known as kriging: a method to interpolate an unknown objective function.
Gaussian Process (GP)
Bonus: would an arbitrary function of input pairs $x$ and $x'$ be a valid covariance function?
The answer is no, as it has to be positive semidefinite.
In this way the intersection of the covariance matrices for multiple features can have a global minima. More information and geometrical interpretation here.
Gaussian Process (GP)
Hyperparameters
The characteristics of GP, or its ability to approximate the unknown function are dependent both on the choice of the covariance function and the values of the hyperparameters. The hyperparameters are usually either choosen manually based on the physics, or obtained from the maximum likelihood fit (log-likelihood fit, maximum a posteriori fit) during the optimization.
- Lengthscale $l$ : controls the scaling of different input dimensions, i.e. how fast the objective function is expected to change from observed points, how smooth the function is.
- small lengthscale = function values can change quickly
- large lengthscale = function changes slowly
- Signal variance $\sigma^2$: a scaling factor to be multiplied to the kernel function (explained next), it is essentially equivalent to normalizing/scaling the objective function.
- small signal variance = functions stay close to their mean value
- Noise variance $\sigma_\mathrm{n}^2$: magnitude of the noise in the observed values, how much noise is expected to be present in the data.
Gaussian Process (GP)
Covariance functions (kernels)
Some of the commonly used kernels are listed below can be found here. They can also be combined to build more complex kernels representing the underlying physics of the objective function.
In this notebook we will use a scaled radial basis function (RBF) kernel $$k_{\mathrm{RBF}} (x,x') = \exp\left(-\frac{d_{x,x'}^2}{2 l^2}\right),$$
where:
- $l$ = lengthscale
- $ d_{x,x'} := ||x - x'||^2 $ is the Euclidean distance between the two points
It is also known as squared exponential (SE). This resembles a normal Gaussian distribution.
It is more or less the default choice of kernel for GPs if one does not have a special assumption on the objective function.
Part II: Implementation of Algorithm with Gaussian Processes
BoTorch: Bayesian Optimization in PyTorch
- BoTorch is the leading Python library to implement Bayesian optimization.
It is built on top of PyTorch, which is an optimized tensor library for deep learning using GPUs and CPUs.
- A tensor is an algebraic object that may map between different objects such as vectors, scalars, and even other tensors. It can be easily understood as a multidimensional matrix/array.
- These objects allow to easily carry out machine learning computations in problems with many features, weights, etc.
- In PyTorch, a tensor is a multi-dimensional matrix containing elements of a single data type.

image from Working with PyTorch tensors
BoTorch: Bayesian Optimization in PyTorch
- Accelerated computing = when we add extra hardware to accelerate computation, like GPUs (needed in deep machine learning).
- GPU: many "not-so-intelligent" cores that are parallelizable. They can carry out specific operations in a very efficient way, e.g. tensor cores perform very efficient sparse tensor multiplication.
- We will be working with torch tensors in this notebook! (instead of the usual numpy arrays.) This means you could execute this code on a GPU if you have access to one with a simple command
torch.device("cuda").
Build an objective function and create some random observations
Let's assume we want to find the global maximum of this function:
$$f(x) = \sin (2 \pi x) + \epsilon$$Let's start by setting a random seed for reproducibility:
random_seed = 3
rng = torch.random.manual_seed(random_seed)
Create some observation points with noise
xmin, xmax = 0, 1
observations_tot = 10
noise_level = 0.2 # add some white noise to observations
observations_x = torch.rand(observations_tot, 1, generator=rng) * (xmax - xmin) + xmin
observations_y = (torch.sin(observations_x * 2 * np.pi) +
torch.randn(size=observations_x.size(), generator=rng) * noise_level)
Create the objective function (200 samples)
samples = 200
objective_x = torch.linspace(xmin, xmax, samples).reshape(-1, 1)
objective_y = torch.sin(objective_x * 2 * np.pi)
test_X = torch.linspace(xmin, xmax, samples)
plt.plot(observations_x, observations_y, "*", markersize=12, color='black', label="Observations (data)")
plt.plot(objective_x, objective_y, color='orange', label="Objective function (unknown)")
plt.xlabel("X feature")
plt.ylabel("Y target")
plt.legend(loc='upper right', bbox_to_anchor=(1.5, 1), framealpha=1)
<matplotlib.legend.Legend at 0x7f066c3d4be0>

Build your first Gaussian process model
For the covariance function (kernel), we choose a scaled radial basis function (RBF) kernel $$K_\text{Scaled-RBF} (\mathbf{x_1},\mathbf{x_2})= \theta_\text{scale} \exp\left( - \frac{1}{2}(\mathbf{x_1} - \mathbf{x_2})^\top \Sigma^{-2} (\mathbf{x_1} - \mathbf{x_2}) \right),$$
where $\theta_\text{scale}$ is the outputscale parameter, $\Sigma^{2}$ is the covariance matrix. In the simple case, the lengthscales for each input dimension are just the diagonal terms.
See also the GPyTorch documentation for more details.
Define the desired kernel, in this case RBF:
kernel = ScaleKernel(RBFKernel())
Build your GP model with previous observations and selected kernel:
model = SingleTaskGP(train_X=observations_x, train_Y=observations_y, covar_module=kernel)
Hyperparameters
Change the hyperparameters below to the following:
- lengthscale: 0.5
- signal variance: 0.5
- model noise: 0.5
# You can change the GP hyperparameters here
model.covar_module.base_kernel.lengthscale = 0.5 # fill here!
model.covar_module.outputscale = 0.5 # fill here! # signal variance
model.likelihood.noise_covar.noise = 0.5 # fill here!
Visualization of the prior of the GP model
The GP just has a constant mean with some uncertainty.
# Visualize the prior
ax = sample_gp_prior_plot(model, test_X)
ax.set_ylim(-2.5, 2.5);

How do the hyperparameter values affect the drawn samples from the model?
$\implies$ Change the GP hyperparameters that you set before, in the previous cells.
$\implies$ How do you predict that the lengthscale, signal variance, and model noise will affect the shape of the samples? Test your theories!
Visualization of the posterior of the GP model
- With the observations we generated previously we can build the posterior distribution
- Observe the current status of our statistical model compared to our objective function
# You can change the GP hyperparameters here again
model.covar_module.base_kernel.lengthscale = 0.5
model.covar_module.outputscale = 0.5 # signal variance
model.likelihood.noise_covar.noise = 0.5
# Visualize the posterior
sample_gp_posterior_plot(model, test_X, y_lim=(-2,2), n_samples=0, show_true_f=True,
true_f_x= objective_x, true_f_y=objective_y);

Change the number of samples visualized
$\implies$ Do this by changing the value of the n_samples argument in the sample_gp_posterior_plot function in the cell above
$\implies$ Can you understand better how the posterior is built?
Change the hyperparameters again to fit the data by hand (two cells above)
$\implies$ Avoid under- or overfitting
$\implies$ The GP mean should fit the data points as good as possible
We will save the hyperparameters you found for comparison later:
manual_lengthscale = float(model.covar_module.base_kernel.lengthscale)
manual_signal_variance = float(model.covar_module.outputscale)
manual_model_noise = float(model.likelihood.noise_covar.noise)
Guide your hyperparameter setting!
- One can use prior knowledge (experience, archive data, ...) to constrain or even fix the Gaussian process hyperparameters.
- Another approach is to dynamically adapt / fit the hyperparameters to the data.
In BoTorch there is a convenient helper function fit_gpytorch_mll to fit the hyperparameters of the Gaussian process model to the data using marginal log-likelihood fits.
Note: fit_gpytorch_mll is introduced in botorch version 0.7.2, if you are using a older python and botorch version, you can use the alternative fit_gpytorch_model function, which will be deprecated for future release.
- In this approach, the hyperparameters are varied until the likelihood is maximized
In the cell below, the ExactMarginalLogLikelihood function takes a likelihood object as argument, which is an attribute of the model we defined before:
mll = ExactMarginalLogLikelihood(model.likelihood, model)
Now let's perform the fit of the hyperparameters:
fit_gpytorch_mll(mll); # carries out the fit
# Show the results
sample_gp_posterior_plot(model, test_X, y_lim=(-2,2), n_samples=0,
show_true_f=True, true_f_x= objective_x, true_f_y=objective_y);

Now the GP model nicely fits the data!
$\implies$ What causes that the model is not completely following the true objective function?
Let's compare manual and automatically fitted hyperparameters
$\implies$ Execute the cell below
$\implies$ Are the values very different?
print('Manual hyperparameters')
print('- Lengthscale: ', manual_lengthscale)
print('- Signal variance: ', manual_signal_variance)
print('- Model noise: ', manual_model_noise)
print('')
print('Fitted hyperparameters')
print('- Lengthscale: ', np.round(float(model.covar_module.base_kernel.lengthscale), 2))
print('- Signal variance: ', np.round(float(model.covar_module.outputscale), 2))
print('- Model noise: ', np.round(float(model.likelihood.noise_covar.noise), 2))
Manual hyperparameters - Lengthscale: 0.5 - Signal variance: 0.5 - Model noise: 0.5 Fitted hyperparameters - Lengthscale: 0.18 - Signal variance: 0.59 - Model noise: 0.01
Build an acquisition function
In Bayesian optimization, one uses an acquisition function to measure how interesting it would be to sample the function $f$ at a point $x$.
The acquisition function $\alpha$ is built based on the GP posterior, e.g. a probablistic surrogate model of the underlying function.
BoTorch has implemented a variety of common acquisition functions, see documentation.
In this tutorial we will use the Upper Confidence Bound (UCB) function.
$$ \alpha_\text{UCB} = \mu (x) + \sqrt{\beta} \sigma(x),$$where $\mu$ and $\sigma$ are the GP posterior mean and standard deviation respectively.
$\implies$ $\beta$ is a hyperparameter controlling the exploration-exploitation trade-off
Explore how the UCB acquisition function behaves
$\implies$ Change the beta argument of the UpperConfidenceBound function in the cell below
$\implies$ What does a larger beta yield?
acq_UCB = UpperConfidenceBound(model, beta=4)
plot_acq_with_gp(model, observations_x, observations_y, acq_UCB, test_X, show_true_f=True,
true_f_x= objective_x, true_f_y=objective_y)

Try other acquisition functions
$\implies$ Try expected improvement and probability of improvement by executing the cells below
acq_EI = ExpectedImprovement(model,best_f=float(model.train_targets.max()))
plot_acq_with_gp(model, observations_x, observations_y, acq_EI, test_X, show_true_f=True,
true_f_x= objective_x, true_f_y=objective_y)

acq_PI = ProbabilityOfImprovement(model, best_f=float(model.train_targets.max()))
plot_acq_with_gp(model, observations_x, observations_y, acq_PI, test_X, show_true_f=True,
true_f_x= objective_x, true_f_y=objective_y)

What are the different sampling strategies of different acquisition functions?
$\implies$ Which one is closer to finding the global maximum?
Bonus: Bayesian exploration
- Instead of doing optimization, we can tweak the acquisition function to only learn about the objective function
- For example, instead of using $\mu(x) + \sqrt{\beta}\sigma(x)$ as in UCB, we can choose the acquisition to be $\alpha(x)= \sigma(x)$.
- In this way, we will only sample the function where the uncertainty is large.
Part III: Application to Beam Positioning and Focusing in a Linac
Beam positioning and focusing task at ARES Experimental Area (EA)
We would like to focus and center the electron beam on a diagnostic screen using 2 corrector and 3 quadrupole magnets.

Look at the ARESEA environment
We formulated the ARESEA task as an OpenAI Gym environment, which is a common approach for Reinforcement learning projects. This allows our algorithm to easily interface with both the simulation and real machine backends.
In this part, you will get familiar with the environment for the beam focusing and positioning at ARES accelerator.
First, let's create the environment.
# Create the environment
env = ARESEA()
# Wrap the environment with some utilities:
env = RescaleAction(env, -1, 1) # Normalize the action space to [-1,1]^n
env.reset();
Get familiar with the Gym environment
$\implies$ Change the magnet values, i.e. the actions
$\implies$ The actions are normalized to 1, so valid values are in the [0, 1] interval
$\implies$ The values of the action list in the cell below follows this magnet order: [Q1, Q2, CV, Q3, CH]
$\implies$ Observe the plot below, what beam does that magnet configuration yield? can you center and focus the beam by hand?
action = [0, 0, 0, 0, 0] # fill here! ]
action = np.array(action)
Perform one step: update the env, observe new beam!
env.reset()
observation, reward, done, info = env.step(action)
fig = plt.figure()
fig.set_size_inches(16, 4)
ax = plt.Axes(fig, [0.0, 0.0, 1.0, 1.0])
ax.set_axis_off()
fig.add_axes(ax)
img = env.render(mode="rgb_array")
ax.imshow(img);


Take several steps in the environment
$\implies$ Run the cell below, which will perform a linear scan of the values corresponding to the vertical corrector CV
$\implies$ What influence does CV have on the beam?
env.reset()
steps = 10
for i in range(steps):
env.step(np.array([0.2, -0.2, -.5 + 1 / steps * i, 0.3, 0]))
img = env.render(mode="rgb_array")
ax.imshow(img)
display(fig)
clear_output(wait=True)
time.sleep(0.5)

Set a target beam you want to achieve
$\implies$ Let's define the position $(\mu_x, \mu_y)$ and size $(\sigma_x, \sigma_y)$ of the beam on the screen
$\implies$ Modify the target_beam list below, where the order of the arguments is $[\mu_x,\sigma_x,\mu_y,\sigma_y]$
$\implies$ Take into account the dimensions of the screen ($\pm$ 2e-3 m)
$\implies$ The target beam will be represented by a green circle on the screen
target_beam = [0, 5e-4, 0, 7e-4] # fill here! ]
env = ARESEA(target_beam_mode="constant",target_beam_values=target_beam,
magnet_init_mode="constant", magnet_init_values=[15, -5, 1e-3, 5, 2e-3])
env = RescaleAction(env, -1, 1) # Normalize the action space to [-1,1]^n
observation, _ = env.reset()
env.render()

Implementation of a full Bayesian optimization loop
def bayesian_optimize(env: gym.Env, last_observation, init_mode="current", n_steps=50,
acquisition="UCB", beta=2, n_init=5, max_step_size:float=0.5, set_to_best=True,
random_seed=None, show_plot=False, proximal=None,time_sleep=0.2):
##################################################################
# Some preliminary settings
if random_seed is None:
random_seed = torch.random.seed() # random
rng = torch.random.manual_seed(random_seed)
# Initialization: some initial samples are needed to build a GP model
# First sample from the reset observation
initial_action = scale_action(env, last_observation)
if init_mode=="current":
X = torch.tensor([initial_action]).reshape(1, -1)
while len(X)<n_init:
last_action = X[0].detach().numpy()
bounds = get_new_bound(env, last_action, max_step_size)
new_action = np.random.uniform(low=bounds[0], high=bounds[1])
new_action_tensor = torch.tensor(new_action, dtype=torch.double).reshape(
1, -1
)
X = torch.cat([X,new_action_tensor])
else: # sample purely randomly
X = torch.tensor([], dtype=torch.double)
while len(X)<n_init:
new_action = env.action_space.sample()
new_action_tensor = torch.tensor(new_action, dtype=torch.double).reshape(
1, -1
)
X = torch.cat([X,new_action_tensor])
Y = torch.zeros(n_init,1,dtype=torch.double)
# sample initial points
for i,x in enumerate(X):
_, reward, _, _ = env.step(x.numpy())
Y[i] = reward
if show_plot:
fig = plt.figure()
fig.set_size_inches(16,4)
ax_progress = plt.Axes(fig, [0.0, 0.0, 0.25, 1.0])
ax = plt.Axes(fig, [0.25, 0.0, 1.0, 1.0])
ax.set_axis_off()
fig.add_axes(ax_progress)
fig.add_axes(ax)
ax_progress.set_xlabel("Steps")
ax_progress.set_ylabel(r"log(MAE($b_\mathrm{current}, b_\mathrm{target}$))")
ax_progress.set_title(f"Best objective: {float(Y.max())}")
##################################################################
# Actual BO logic
for i in range(n_steps):
# Fit GP model to the observed data
kernel=ScaleKernel(MaternKernel())
model = SingleTaskGP(X, Y,covar_module=kernel, outcome_transform=Standardize(m=1))
# model.likelihood.noise = 1e-2
# model.likelihood.noise_covar.raw_noise.requires_grad_(False)
mll = ExactMarginalLogLikelihood(model.likelihood, model)
fit_gpytorch_mll(mll)
# Build acquisition
if acquisition=="UCB":
acq = UpperConfidenceBound(model, beta=beta)
elif acquisition=="EI":
ymax = float(Y.max())
acq = ExpectedImprovement(model, best_f=ymax)
if proximal is not None:
acq = ProximalAcquisitionFunction(acq,proximal_weights=proximal)
# Choose next action
new_bound = get_new_bound(env,X[-1].detach().numpy(), max_step_size)
x_next, _ = optimize_acqf(acq, bounds=torch.tensor(new_bound),
q=1, num_restarts=16, raw_samples=256,
options={"maxiter": 200},)
# Apply the action
observation, reward, done, _ = env.step(x_next.numpy().flatten())
# Append data (with correct shape)
Y = torch.cat([Y,torch.tensor([[reward]])])
X = torch.cat([X,torch.tensor(x_next).reshape(1,-1)])
# Plotting
if show_plot:
img = env.render(mode="rgb_array")
ax.imshow(img)
ax_progress.clear()
ax_progress.plot(Y.detach().numpy().flatten())
ax_progress.set_title(f"Best objective: {float(Y.max()):.2f}")
ax_progress.set_xlabel("Steps")
ax_progress.set_ylabel(r"log(MAE($b_\mathrm{current}, b_\mathrm{target}$))")
display(fig)
clear_output(wait=True)
time.sleep(time_sleep)
# Check termination
if done:
print("Target beam is reached")
set_to_best=False # no need to reset
break
# Set to best observed if not reaching target in the allowed steps
if set_to_best:
x_best = X[Y.flatten().argmax()].numpy()
env.step(x_best)
# Plotting
if show_plot:
# print(f"Best objective: {float(Y.max())}")
img = env.render(mode="rgb_array")
ax.imshow(img)
display(fig)
clear_output(wait=True)
time.sleep(time_sleep)
# Return some information
opt_info = {
"X": X,
"Y": Y,
"best": Y.max(),
}
return opt_info
Let's apply Bayesian optimization to this problem
- We will use the loop implemented in the cell above
- In order to quantify how the algorithm is performing, we will use the log maximum absolute error (L1 error) as metric:
- We do this because using just the difference between the target and the real beam is very small (sub mm)
Running Bayesian optimization
$\implies$ Run the cell below and observe the optimization. Did it achieve the target? How did the performance metric evolve during the optimization?
$\implies$ Change the max_step_size argument. This indicates how much each action changes per step. What do you observe if the steps are too large?
$\implies$ Do you think that adding more iteration steps will help?
$\implies$ Can you think of other ways of solving this focusing and steering problem automatically?
env = ARESEA(target_beam_mode="constant", target_beam_values=target_beam, magnet_init_mode="constant",
magnet_init_values=[15, -5, 1e-3, 5, 2e-3])
env = RescaleAction(env, -1, 1) # Normalize the action space to [-1,1]^n
observation, _ = env.reset()
opt_info = bayesian_optimize(env, last_observation=observation, n_steps=50, max_step_size=0.1,
show_plot=True, beta=0.2, time_sleep=0.1);
# Another advanced technique "Proximal biasing" uses soft step size limit
# opt_info = bayesian_optimize(env, last_observation=observation,n_steps=50,max_step_size=1,
# show_plot=True, beta=0.2, proximal=torch.ones(5)*0.5)


Exploration and exploitation with acquisition functions
$\implies$ Change the beta argument of the bayesian_optimize function in the cell below to 2. What is different in this optimization compared to the previous one? How does the performance metric evolve?
$\implies$ Use a different acquisition function, like expected improvement "EI"
env = ARESEA(target_beam_mode="constant", target_beam_values=target_beam, magnet_init_mode="constant",
magnet_init_values=[15, -5, 1e-3, 5, 2e-3])
env = RescaleAction(env, -1, 1) # Normalize the action space to [-1,1]^n
observation, _ = env.reset()
### Change the value of beta, see how it impacts the optimization process;
### Or switch to another acquisition
beta = 2.0
acquisition = "UCB"
opt_info = bayesian_optimize(env, observation, n_steps=40, acquisition=acquisition, beta=beta,
max_step_size=0.3, show_plot=True, time_sleep=0.05);


Summary¶
Bayesian Optimization (BO):
- is a numerical global optimization method for black-box functions.
- uses a Gaussian process (GP) as a statistical surrogate model of the objective.
- a GP is characterized by its mean and covariance (kernel) function.
- Hyperparameters can be dynamically fitted to the data.
- Prior knowledge can be included for setting the priors.
- uses the acquisition function to guide the optimization
- One should choose an acquisition function suitable for the task.
- Hyperparameters of the acquisition function also affect the optimization behaviour.
- is an optimization method and not designed for control tasks.
- is adequate for a moderate amount of dimensions (~100)
Literature¶
Hopefully you have learned something about BO, if you want to try it yourself afterwards, below are some interesting resources.
Publication: Various applications of BO in accelerator physics¶
- BO Review Paper: Bayesian Optimization Algorithms for Accelerator Physics
- KARA, KIT: Bayesian Optimization of the Beam Injection Process into a Storage Ring Beam injection optimization using BO.
- LCLS, SLAC: Bayesian optimization of FEL performance at LCLS, Bayesian Optimization of a Free-Electron Laser FEL performance tuning with quadrupoles
- LUX, DESY: Bayesian Optimization of a Laser-Plasma Accelerator LPA tuning to improve bunch quality with laser energy, focus position, and gas flows.
- Central Laser Facility, Rutherfold UK: Automation and control of laser wakefield accelerators using Bayesian optimization, LWFA performance tuning with different objective functions
- PSI, SwissFEL: Tuning particle accelerators with safety constraints using Bayesian optimization Adaptive and Safe Bayesian Optimization in High Dimensions via One-Dimensional Subspaces : BO with safety constraints to protect the machine
- SLAC, ANL: Multiobjective Bayesian optimization for online accelerator tuning, multiobjective optimization for accelerator tuning,Turn-key constrained parameter space exploration for particle accelerators using Bayesian active learning, Bayesian active learning for efficient exploration of the parameter space. Differentiable Preisach Modeling for Characterization and Optimization of Particle Accelerator Systems with Hysteresis hysteresis modelling with GP, and application of hysteresis-aware BO.
Books and papers on Bayesian optimization in general¶
- C. E. Rasmussen and C. K.I. Williams, Gaussian Processes for Machine Learning: the classic textbook of Gaussian process.
- Eric Brochu, A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning: a comprehensive tutorial on Bayesian optimization with some application cases at that time (2010).
- Peter I. Frazier, A Tutorial on Bayesian Optimization: a more recent (2018) tutorial paper covering the most important aspects of BO, and some advanced variants of BO (parallel, multi-fidelity, multi-task).
Bayesian Optimization / Gaussian Process packages in python¶
Below is an incomplete selection of python packages for BO and GP, each with its own strength and drawback.
- scikit-learn Gaussian processes : recommended for sklearn users, not as powerful as other packages.
- GPyTorch : a rather new package implemented natively in PyTorch, which makes it very performant. Also comes with a Bayesian optimization package BOTorch, offering a variety of different optimization methods (mult-objective, parallelization...). Both packages are being actively developed maintained; recommended state-of-the-art tool for BO practitioners.
- GPflow : a GP package implemented in TensorFlow, it also has a large community and is being actively maintained; The new BO package Trieste is built on it.
- GPy from the Sheffield ML group : A common/classic choice for building GP model, includes a lot of advanced GP variants; However in recent years it is not so actively maintained. It comes with the accompanying Bayesian optimization package GPyOpt, for which the maintainance stoped since 2020.
- [Dragonfly] : a open-source BO package; offers also command line tool, easy to use if you are a practitioner. However if one has less freedom to adapt and expand the code.
C.f. the wikipedia page for a more inclusive table with GP packages for other languages.
Other Resources¶
- Another similarly structured BO tutorial using the scikit-learn GP package, given at the 2022 MT ARD ST3 ML Workshop